AIDAVA Use Cases
Availability of integrated, high-quality personal health data (PHD) remains limited, with impact on quality and costs of care and limiting possibilities for research and analytics. Indeed, PHD is currently distributed, heterogeneous, captured through different modalities, with variable quality. Interoperability and reuse of PHD remains a major challenge that will be addressed in AIDAVA AIDAVA wants to address interoperability and reusability of PHD by working on two use cases and demonstrating the principle of “curate once, use many times”.
Use Case 1: Breast Cancer Registry (Hospital Centric)
Development and maintenance of an EU Breast Cancer registry by defining a set of data elements that can be derived from AIDAVA to form a federated registry. Each clinical site will provide these extracts; a federated query across all three sites will demonstrate interoperability and reuse.
Use Case 2: CVD Longitudinal Health Record (Patient Centric)
Management of longitudinal health records of CVD patients with display of the record for the patient through the same application across sites; and with computation of the SMART Risk Score, a 10-year risk score for vascular events. The score will be computed automatically in the three sites with the same algorithm, based on the extract issued from AIDAVA.
AIDAVA will work through the following steps:
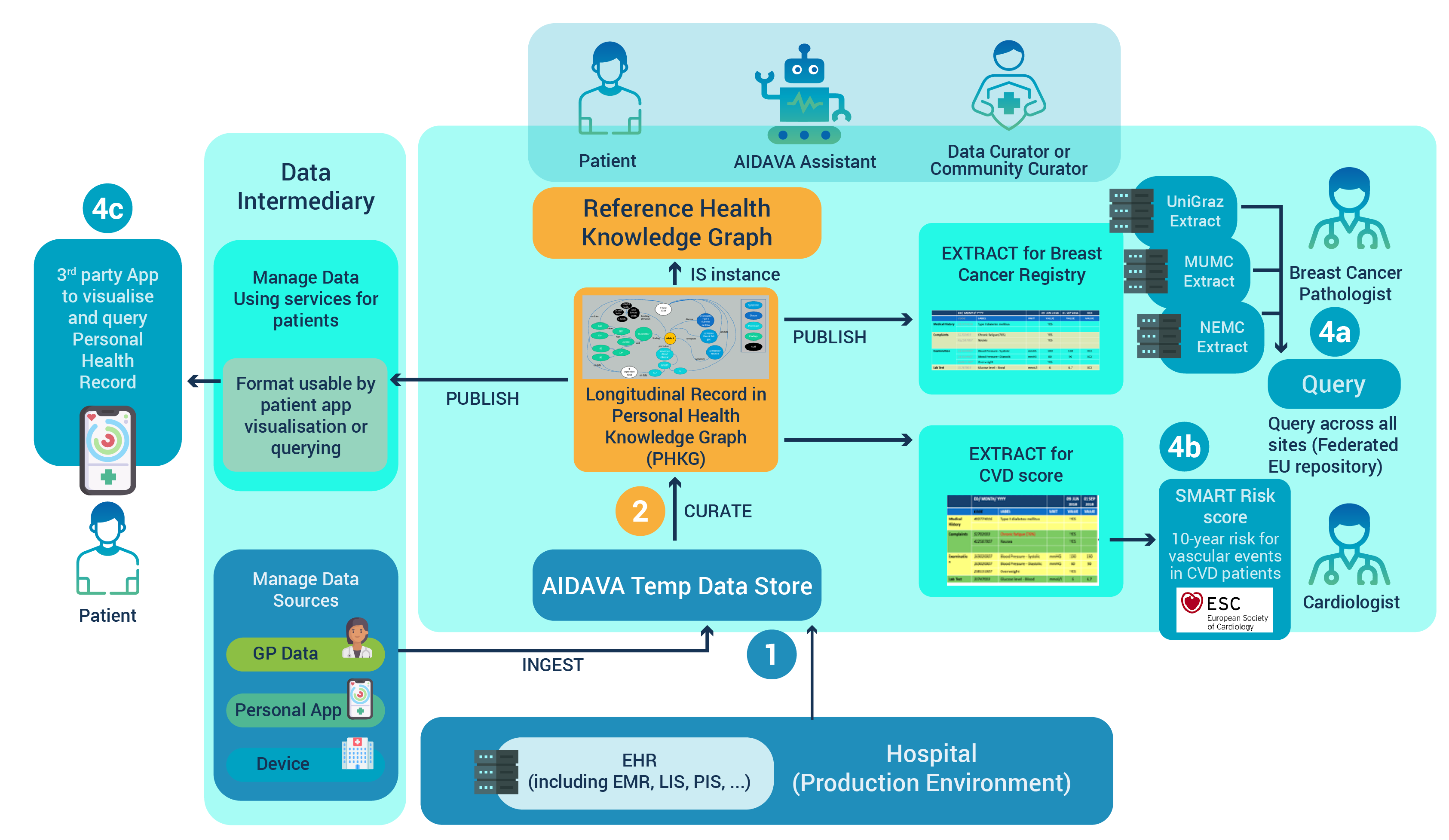
Data Ingestion
Transfer and pooling of data from different data sources, from the hospital or from the health data intermediary acting on behalf of the patient
Data Curation
Harmonisation and integration of heterogeneous data sources and transformation into a Personal Health Knowledge Graph (PHKG). AIDAVA will maximise automation on this step by orchestrating multiple (AI based) curation tools based on the interoperability issue to be solved; patients and expert data curators will be asked to complement information whenever relevant. Data quality checks will be performed on the resulting PHKG.
Data Publishing
Transformation of the PHKG into a format required for data consumption and secondary data use. From the PHKG, many transformations are possible supporting different use cases enabling the "curate once, use many times"' principle of the AIDAVA project.
- Extract for local instance of an “EU” Breast Cancer Registry (Use Case 1)
- Extract to compute the SMART risk score (Use Case 2)
- Extract to visualise and query the patient longitudinal record (Use Case 2 – also provided in Use Case 1 as an option to the patients); to be done across three sites with a 3rd party app being identified
Data Use
Usage of the respective extracts to meet a specific need
- Federated query across the three sites mimicking a “federated EU registry” (Use Case 1)
- Computation, display and comparison over time of the SMART risk score of the related patient (Use Case 2)
- Display of the patient longitudinal record with selected 3rd party app